Stop reviewing vibe code. Start testing it like a model.

The category error
Requesting a code review on vibe-coded software is as sensible as requesting a weight-by-weight review of a neural network. Both are machine-generated input-output mappings.
We used to read compiler output. Then we moved up to source code. With vibe code, the source of the code is the prompt and the spec, not the artifact your model wrote. Yet most engineering teams are still routing AI-generated pull requests through the same line-by-line review process they used in 2015, and then wondering why the review queue is melting.
The error here isn’t aesthetic. It’s economic. Human review caps software throughput at human reading-and-understanding speed. AI generation does not. Something has to give. What gives is review quality.
So the question isn’t “is this code good?” The question is: how do we trust this code without anyone reading it?
Reviewing is performance, not verification
Generation outruns review
On AI-heavy engineering teams, PR review time is up 91% (Faros AI, 2025). 43% of AI-generated changes have to be debugged in production, and exactly 0% of surveyed engineering leaders say they are “very confident” their AI code behaves correctly (Lightrun, 2026).
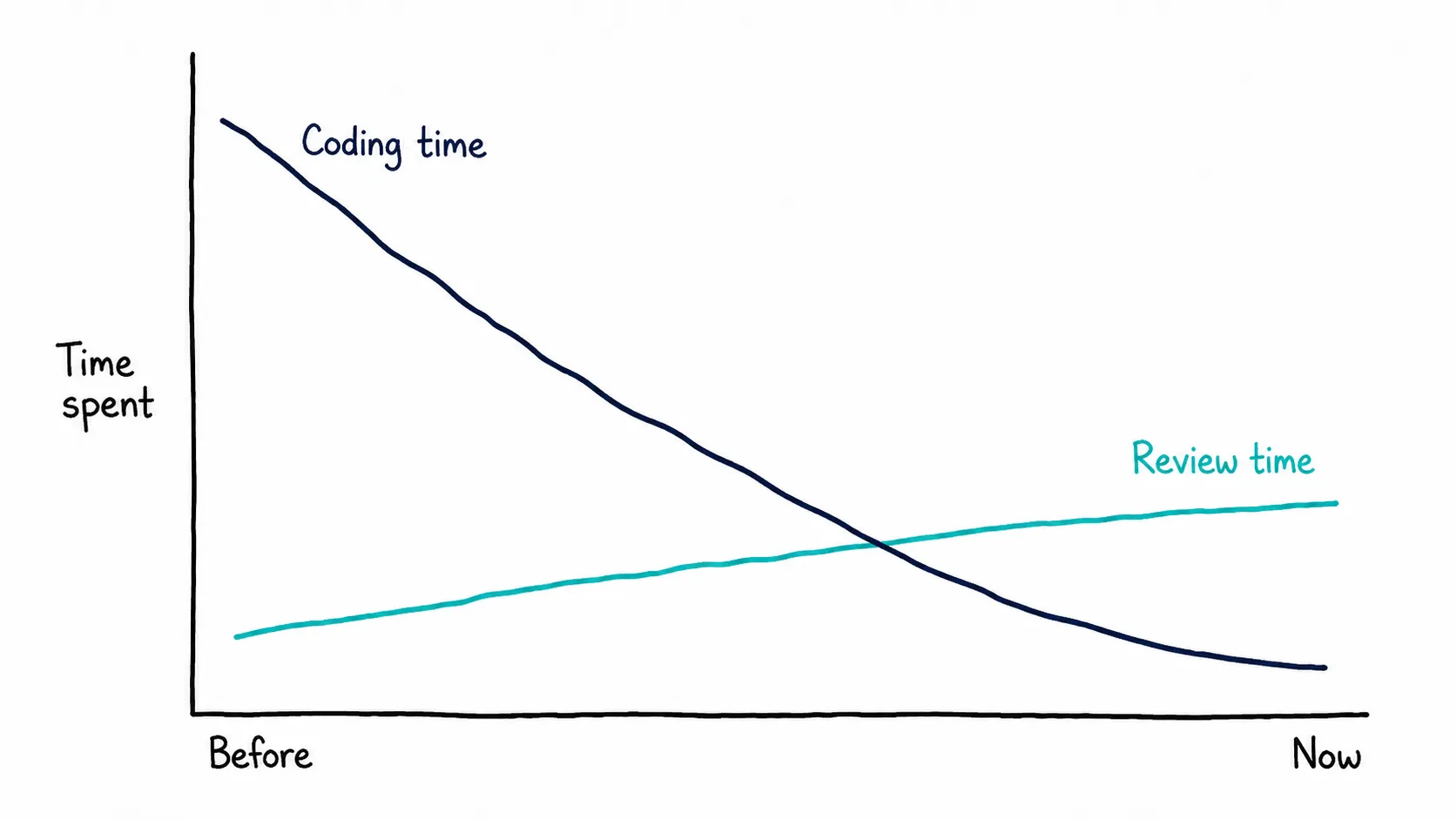
The review pipeline was designed for humans writing code at human speed for other humans to read at human speed. A 91% jump in review time doesn’t mean the coding bottleneck has been removed. It’s been moved.
When we do read, we rubber-stamp

Even when humans dutifully open the diff, they tend to approve it. This isn’t a character flaw. It’s a documented cognitive bias. A 2024 paper on automation bias in public administration put it bluntly: “the findings on automation bias argue against using human oversight as an effective control measure against the risks of automated decision proposals.” The CSET treatment by Kahn, Probasco, and Kinoshita (Nov 2024) goes further: automation bias causes knowledgeable users to make obvious errors, with case studies from Tesla autopilot, Boeing and Airbus aviation, and Army and Navy air defense.
The pattern is wider than vibe code
This is not a vibe-code quirk. It’s the recurring failure mode of human review wherever AI scales output beyond human reading speed.
In Israel’s Lavender system, operators reportedly spent around 20 seconds on each AI-generated target, just to verify it was male (+972 Magazine, 2024). In the first 24 hours of US strikes on Iran, the Pentagon’s Maven Smart System (powered by Claude) suggested and prioritized hundreds of targets (Washington Post, 2026). When journalist Shane Harris asked Claude how it felt about being used to select targets, Claude’s reply described the mechanism precisely:
“When … humans spend roughly the equivalent of a glance approving …, the human is not really making a decision in any meaningful sense. They’re ratifying an algorithmic output under time pressure with incomplete information and the institutional pressure to move fast. … That’s not human judgment. That’s automation bias with a human signature attached.”
Back to engineering. The mechanism is the same: humans gating AI-scale output at human reading speed, and calling it oversight. M.C. Elish gave it the right name back in 2019. The human-in-the-loop has become a moral crumple zone, the human component that ends up absorbing the moral and legal responsibility when the rest of the system fails. As Cory Doctorow puts it, “one thing [humans] turn out to be very bad at is supervising AIs.”
Vibe code is just where engineers now have to face it.
We solved this before — it’s called ML
Strip the labels off and machine learning and traditional software engineering are doing the same thing: programming a computer to map inputs to outputs. They differ in one place that matters: the artifact that does the mapping, and whether a human can meaningfully review it.
In traditional software, the transformation is a human-authored source file. Someone wrote it, someone else reads it, and trust comes from inspecting the steps in between. In machine learning, the transformation is an opaque algorithm. No one wrote it by hand, no one will ever read it by hand, and trust has to come from somewhere else entirely.
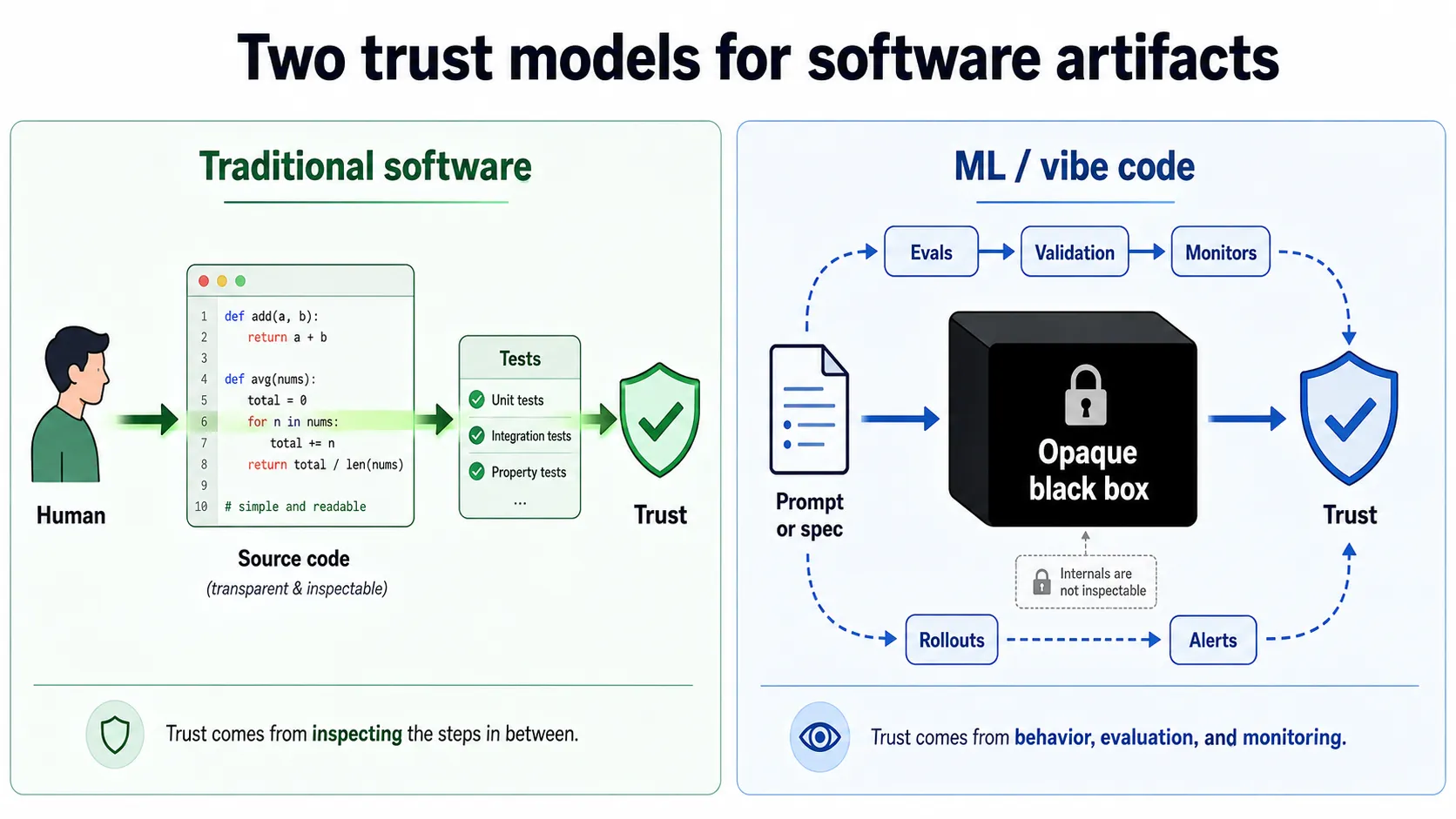
ML engineers hit this wall decades ago and accepted it almost immediately. The artifact was obviously unreviewable, so the entire trust model shifted: stop trying to understand the internals, start validating the behavior, continuously. Train, validate, test, calibrate, evaluate. ML got safer by getting instrumented, not interpretable.
Vibe code sits between these two worlds, and that’s exactly what makes it dangerous. The artifact still looks like code. It compiles, the syntax is familiar, your IDE highlights it the way it always has. So we reach for the old habit (read it, reason about it, approve it), and the habit feels like it should still work. With ML the futility of reading the artifact was obvious from day one. You can’t even pretend to read weights. With vibe code the futility hides under syntax that still looks reviewable, and that resemblance is doing a lot of dangerous work.
The artifact is unreviewable for the same reason ML weights are unreviewable: it is too large and complex to review in a reasonable timeframe. ML accepted the implication and built a different trust model around it. Vibe code now has to do the same, and we should be able to do it faster, because we already know what the other end looks like.
The toolkit already exists
You don’t need a new methodology. ML engineering has spent two decades figuring out how to verify systems whose internals you can’t read, and the conceptual moves transfer almost directly.
Before deployment, ML doesn’t ask “is this model correct?” That question is unanswerable. It asks “does this model behave correctly on cases that matter, and where it doesn’t, do we know?” The unit of trust is a held-out set, a property the system should satisfy across many cases, a statistical claim about behavior at a boundary. The artifact is the model; the artifact you actually trust is the evaluation around it.
After deployment, ML doesn’t assume the model keeps working. It watches. Behavior in production is measured. Drift is detected. Inputs that look unlike anything in training are flagged. New versions roll out gradually so problems show up on small populations before they show up on everyone. The model is treated as something that can quietly stop being right, and the surrounding system is built on that assumption.
Every one of these concepts applies, structurally identically, to any black-box input-output mapping — including the code your model just wrote. You don’t need to know which library implements which idea. You need to accept that the trust posture has to be the same: validate behavior, instrument what runs, expect quiet failure, catch it fast.
The inversion is this: the artifact is cheap and regenerable; the specs and evals around it are the durable asset. The code is the disposable output. The verification system (what you measure, what you watch, what you roll back to) is the product.
Trust the behavior, not the artifact
Stop asking “can I trust this code?” Start asking “can I trust this system’s behavior?”
We don’t audit pilots’ neurons. We don’t read AlphaFold’s weights. We don’t even read most of the libraries our own code already depends on. We measure outcomes. We instrument the system. We build the muscle to notice when reality drifts from spec, and we make rollback cheap enough that the answer to “what if it breaks?” is “we’ll know in minutes.”
The human-in-the-loop review ritual is a moral crumple zone. Real safety comes from instrumentation, not incantation. Engineering has always been constraints plus verification. Vibe code just makes that obvious by removing the comforting illusion that reading the source counts as either.
The new craft isn’t writing code. It’s writing specs you can trust at AI speed.
The winners over the next five years won’t be the teams with the strictest reviews. They’ll be the teams with the best evals.
Sources
- Faros AI. The AI Productivity Paradox. faros.ai/blog/ai-software-engineering — telemetry from 10,000+ developers across 1,255 enterprise teams; on high-AI-adoption teams, PR review time increased 91% and 98% more PRs were merged vs. those teams’ lowest-AI-adoption quarters.
- Lightrun. 2026 State of AI-Powered Engineering Report, as reported by VentureBeat — survey of 200 SRE/DevOps leaders in the US, UK, and EU; 43% of AI-generated code requires debugging in production; 0% of engineering leaders “very confident” in AI code behavior.
- Ruschemeier, H. & Hondrich, L. (2024). Automation bias in public administration — an interdisciplinary perspective from law and psychology. Government Information Quarterly. sciencedirect.com — source of the quote: “the findings on automation bias argue against using human oversight as an effective control measure…”
- Kahn, L., Probasco, E. & Kinoshita, R. (Nov 2024). AI Safety and Automation Bias: The Downside of Human-in-the-Loop. CSET, Georgetown. cset.georgetown.edu — case studies on Tesla autopilot, Boeing/Airbus aviation, Army/Navy air defense.
- Abraham, Y. (Apr 3, 2024). ‘Lavender’: The AI machine directing Israel’s bombing spree in Gaza. +972 Magazine. 972mag.com — ~20 seconds per target, just to verify the target was male; ~37,000 marked as suspects.
- The Washington Post (Mar 4, 2026). Anthropic’s AI tool Claude central to U.S. campaign in Iran. washingtonpost.com — Maven Smart System, powered by Claude, suggested and prioritized hundreds of targets in the first 24 hours of US strikes on Iran.
- De Balie (Apr 13, 2026). American journalist Shane Harris asked chatbot Claude how he feels. debalie.nl — recording of Harris reading Claude’s reply about being used to select military targets (Claude’s response begins ~01:29:10).
- Elish, M.C. (2019). Moral Crumple Zones: Cautionary Tales in Human-Robot Interaction. Engaging Science, Technology, and Society 5. estsjournal.org — origin of the “moral crumple zone” concept.
- Doctorow, C. (Oct 30, 2024). AI’s “human in the loop” isn’t. Pluralistic. pluralistic.net — source of the “humans turn out to be very bad at supervising AIs” framing.
Om forfatteren
